Placing language in an integrated understanding system: Next steps toward human-level performance in neural language models
By James McClelland, Felix Hill, Maja Rudolph, Jason Baldridge, Hinrich Schutze.
Most our current models focus on language-internal tasks, limiting their ability to perform tasks that depend on understanding situations. Lack memory for recalling prior situations. This paper sketches a framework for future models of understanding.
Cf. Rumelhart’s handwriting (in context can be read: went vs. event).

“A boy hit a man with a [bat|beard]”
- Semantics: “bat” as the instrument used to hit
- Syntax: “bat” as part of the sentence verb phrase: “hit with a bat”
- Syntax: “beard” as part of the noun phrase: “man with a beard”
Elman: “boy [who sees girls] chases dogs” [reduced relative clause]. Model predicting correct verb form (“chases”) - shows sensitivity to syntactic language structure.
Elman trained with tiny, toy languages. NLP ruled by n-grams and structure. In recent 10 years, co-occurence relationships (word2vec I guess).
The model manages to understand hierarchical clustering (?).
John put some beer in a cooler and went out with his friends to play volleyball. Soon after he left, someone took the [beer|ice] out of the cooler. John and his friends were thirsty after the game, and went back to his place for some beers. When John opened the cooler, he discovered that the beer was
Expect: beer → “gone”, ice → “warm”; too hard for RNN. LSTMs don’t fully alleviate the context bottleneck: internal state is fixed vector (how does the 2nd follow from 1st?).
Query-based attention (QBA) works “as Rumelhart envisioned (?)” by mutual constraint satisfaction. I.e. BERT stacks layers of multi-head attention transformers, each constraining the meaning of the corresponding attention head in layer below. BERT’s representations capture structure without it being built-in; emergence.
GPT-3 still fails on “common sense physics”.
Language in an integrated understanding system
What they call situations are actually “categories”? Situations can be concrete, abstract, nested, etc.
Ex. [[[cat on a mat] in a house] in west virginia] are nested categories.
Evidence that humans construct situation representations from language comes from classic work by Bransford and colleagues:
- We understand and remember texts better when we can relate the text to a familiar situation;
- relevant information can come from a picture accompanying the text;
- what we remember from a text depends on the framing context;
- we represent implied objects in memory; and
- after hearing a sentence describing spatial or conceptual relationships, we remember these relationships, not the language itself.
Given “Three turtles rested beside a floating log and a fish swam under it,” the situation changes if “it” is replaced by “them.” After hearing the original sentence, people reject the variant with “it” in it as the sentence they heard before, but if the initial sentence said “Three turtles rested on a floating log,” the situation is unchanged by replacing “it” with “them,” and people accept this variant. Evidence from eye movements shows that people use lin- guistic and nonlinguistic input jointly and immediately (46). Just after hearing “The man will drink,” participants look at a full wine glass rather than an empty beer glass (47). After hearing “The man drank,” they look at the empty beer glass.
Complementary learning systems (CLSs) theory: connections within the neocortex gradually acquire the knowledge that allows a human to understand objects and their properties, link words to objects, understand and communicate about generic and familiar situations.
The Medial Temporal Lobe (MTL) stores an integrated representation of the neocortical system state arising from a situation.
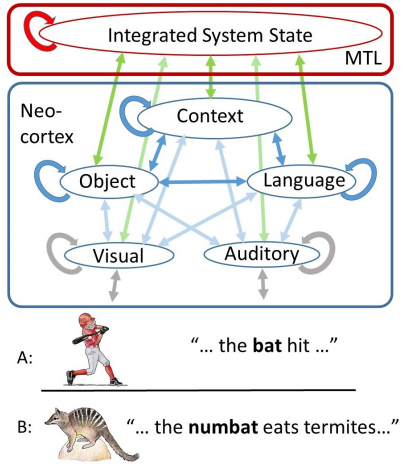
People w/MTL damage have difficulty understanding or producing extended narratives. GPT-3 after training can be viewed as a human without MTL.
Next steps toward a brain and AI-inspired model
Principles
- Mutual constraint satisfaction (think BERT layers)
- Emergence (think insights “just appearing”)
Evaluation via microsituations consisting of Picture-Description (PD) pairs grouped to scenes that form story-length narratives. Language conveyed by text.
The human learner is afforded the opportunity to experience the compositional structure of the environment through his own actions.
They tried some LSTM in this context: F. Hill et al. Environmental drivers of systematicity and generalization in a situated agent. TL;DR lift 20 objects trained to put 10 in some location, can still place the remaining ones with 90% accuracy.
See also:Agents of art · Conformal Classification of Neural Networks · Back to Square One: Artifact Detection, Training and Commonsense Disentanglement in the Winograd Schema · Probing Emergent Semantics in Predictive Agents via Question Answering